前言
最近几周都在升级重构原来的项目,这个项目的业务逻辑代码几乎都是在Oracle数据库中用存储过程实现的,从17年上线到现在,中间经历了很多次需求新增和变更,业务表单也从原来200多个增加到了500多个,数据库的表也超过了1000张,这中间开发和运维一直有些痛点得不到解决。今年部门决定升级Ebs系统,导致这个项目也需要跟着进行升级,正好借此机会进行规范制定和重构,希望能解决部分痛点,提升开发和运维效率。
项目介绍
这个项目主要作用是帮助财务用户把原来在Excel中处理的手工数据放到线上来,用户可以通过上传Excel原始数据,系统帮助进行数据验证和逻辑计算,最后生成财务需要的凭证分录,再次验证通过之后,导入到Ebs系统中,同时在系统中出一些财务报表。说白了就是把原来Ebs做不到的功能,或者不符合国内用户使用习惯的功能拿到这个项目中实现。
项目的架构很简单,前端提供Web页面给用户操作,后端使用java处理Excel导入导出,所有数据在oracle数据库中进行校验和计算,最终导入到其他系统。
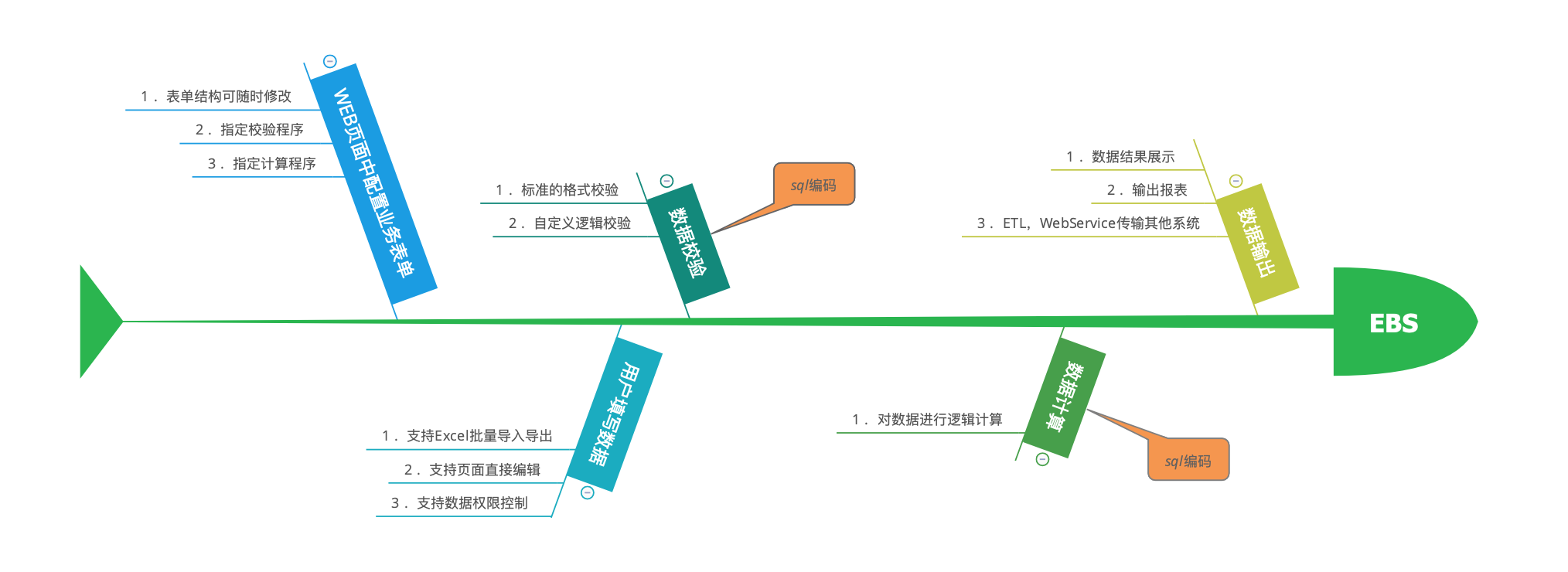
可以发现,这个系统在前端和Java方面是很标准简单的,只是负责配置,然后根据配置生成对应的Web表单,同时提供Excel导入导出,存储过程调用等。它的核心是数据校验和数据计算,这部分都是在oracle数据库通过sql编写的,所以项目存在大量sql代码,升级改造也是针对这一部分。
关于项目的思考
为什么使用sql来处理业务逻辑?
在很多Java项目中,是不会在sql中处理复杂业务逻辑的,基本都是简单的CURD,顶多通过复杂sql或存储过程出一些展示报表。但是在财务软件这个领域不一样,它有数据量大,逻辑复杂,业务多且变更快的特点,还有一个特点是,舍不得在开发团队上投入,大部分上市企业都是采用Oracle的ERP系统,请乙方公司实施,最后交给自己的开发运维团队,通常都是几个人到十几个人,其中一半还是业务和管理。那么只有几个开发的情况下,如何在运维工作之外应对业务和逻辑的快速变更呢?使用sql编程不失为一个好办法,至少在我的知识范围内,没有其他更好替代的语言。采用Sql有如下几个优点:
-
开发速度快
在纯数据处理方面简直无敌,有些复杂的数据计算,使用Java需要创建多个类,各种循环上百行代码,但是使用sql可能就是几行的事情。
-
动态语言
动态语言在变更方面有很大优势,如果使用Java,则在逻辑修改后还需要进行应用发布,使用sql的话,可以瞬间执行立即生效,在线上环境中可以快速解决问题。而且会计规则复杂专业,业务了解之后还要转化成开发听得懂的描述,如果是sql,开发完立即给业务使用,测试有问题马上改,这个过程都是非常高效的,边开发边交流,自然就容易多了。
-
可以专注于业务
使用Sql可以专注于业务逻辑,不必关心工程方面的问题,Sql非常灵活多变,面向过程编程,更加接近“描述问题即解决问题”。
-
Oracle强大稳定
oracle数据库实在是太强大了,运行在服务器上几乎不会出现问题,而且性能也很强大,使用sql编写程序不用担心会把服务器搞挂掉,即使有问题,也大多是当前sql有问题,针对sql进行分析和调优就行了。
现有项目有哪些痛点?
本来想写采用sql编程有哪些痛点?但是仔细思考了一下之后,觉得不太恰当,虽然跟sql相关,但是这些痛点未必是sql导致的。这些问题在17年实施项目的时候并未意识到,后续运维和开发过程中才慢慢体会到。
-
sql代码不标准,混乱难阅读,难修改
项目从开始到现在,经历了多个乙方开发和自己团队开发,由于sql的灵活,实现方式跟开发个人有非常大的关系,同样的逻辑换个人写可能就完全不同。因此换个人来阅读,就需要在理解业务的基础上再去理解上一个人思路,同时由于短短的一段sql可能包含复杂的逻辑,在变更的时候更是不敢轻易下手,在关联五六个表,where条件一大堆的情况下就更痛苦了,不仅需要理解sql,还需要去了解来源表中的数据。总之就是“开发一时爽,重构火葬场”。
-
package不够细分
原来实施的时候package划分不够细,导致现在一个package动不动几万代码,改动一句sql也需要全部编译,发布到生产时也需要整个package发布。如果同时有多个需求在开发,只需要发布其中一个时,还得在生产修改只变化的那部分,这给开发带来了压力,担心发布出错。
-
命名和注释不规范
原来没有相关规范或执行不严,不论是表的命名还是其他对象,都很随意,存储过程中的注释就更随意了,有些技术什么注释都不写,半个月之后让他来看,自己懵了。
如何解决这些痛点?
其实项目中的问题大大小小不止这些,但是这些是最紧要头疼的,在这次升级之前,我们几个技术就进行了讨论,如何解决这些问题?我们最后觉得核心是标准化,没有标准规范约束,在sql语言的特性下,是很难控制项目的质量的,尤其是乙方技术做完就走,更是随意。最后我们决定做这几个事情:
-
增加命名规范
表的命名根据业务模块加统一前缀,根据业务类型加统一后缀,这样一看到表就大致知道它的作用,修改模块也能缩小表的范围。 同样视图,序列,package,procedure,function也都增加命名规范,能一眼看出其模块和类型。 增加procedure中参数的命名规范,根据输入参数,局部变量,输出参数划分前缀,这样在阅读的时候能瞬间分辨出这个是变量还是参数,是否能赋值。 增加注释规范
-
拆分package
将原来的package细分,每个大模块拆分成小模块,再根据其中的存储过程类型划分到工具包,校验程序包,计算程序包。这样后续修改就能影响最小,如果修改工具包中的存储过程或函数,就会意识到可能影响多个地方。 发布也能更加独立,测试压力小,即使出问题也不会影响其他模块功能。
-
标准化
这其实是最重要的,如果说命名规范是帮助开发更好的理解代码,那么标准化就是帮助开发更好的写出易读,质量高,错误少的代码。因为sql难读的最大痛点在于无法限制大家的想象力,不同的人写出来的代码各种各样,有些简单逻辑被写的非常难懂,但是这个能力是无法短期提升的,也无法限制大家的思维。所以标准化非常重要,从更高的层面去思考哪些可以抽象出来形成标准的工具包,在开发过程中强制大家使用,这样就相当于形成了共识,以后阅读其他人代码,一看到对应的工具包就知道是什么作用,这样可以专注理解更少的代码,修改也变得更加容易。同时这样也降低了对开发的要求,很多逻辑不需要他自己去实现,只需要调用基础的工具包就好了。
实践中我们结合校验程序和计算程序的特性,将获取基础信息,解析标准数据,执行动态sql,记录异常错误日志等方面开发成了工具包,提供给其他开发调用。同时增加对执行过程中的日志记录,方便后续运维解决问题。
-
重新整理修改跟外围系统的对接
原来跟外围系统对接,大多通过两种方式,一种是ETL工具,另外一种是dblink,这两种方式在财务管理软件方面可能很常见,但是对应互联网业务系统来说就不太合适了,首先是他们的系统对接通常使用Webservice,大家无需关系数据库类型和地址,按格式要求调用接口就行。但是使用ETL和dblink就不一样了,需要知道对方机器的具体ip,一旦变更还得互相通知,而且直接侵入了他们的数据库,在不同数据库之间还存在技术难度,同时不利于数据安全和审计。 后续我们优先使用Webservice,对于原来ETL和dblink的部分则建立中间库,不再直接进行生产数据库表授权访问。
后记
项目的重构总是不断的,无论现在多好的设计和规范,经过一段时间总会存在各种各样的问题,所以还需要不断思考和重构,提升项目质量。